Healthcare AI News with ScienceSoft’s Expert Analysis

ScienceSoft’s experts explore the latest healthcare AI news through the lens of practical implementation and regulatory compliance. Each analysis is based on publicly available information, industry best practices, and ScienceSoft’s hands-on experience in healthcare IT.
NYU Langone’s AI Notes in Epic Missed Key Facts: What Actually Failed and How to Engineer It Out?
Published: September 2, 2025
On August 13, 2025, NYU Langone Health, a major US academic medical center, reported results from a study of an AI note-generation assistant embedded in the Epic EHR. The tool, based on a general-purpose LLM (unspecified, but likely GPT-4 via Azure OpenAI), uses a prompt developed by the NYU Langone team to draft daily Hospital Course summaries from condensed patient records, with integration provided by Epic.
The study covered 100 general-medicine admissions. Resident physicians edited either AI-generated or physician-written drafts, and attending physicians rated the final notes. AI drafts needed fewer edits (31.5% of text vs. 44.8%), but were 0.98 points worse on the “confabulation-free” (factual accuracy) 1–5 scale.
In its review of the paper, Becker’s Hospital Review named automation bias as the main risk of the proposed solution: clinicians may over-trust polished artificial intelligence output. Consultants at ScienceSoft add that AI tools without proper safety guardrails, such as Langone’s pilot, may actually increase physician workload by adding error-hunting to their responsibilities.
What Are the Safeguards Against AI Errors, and Did NYU Langone Apply Them?
Experts at ScienceSoft identified four widely accepted safeguards against errors in AI output that are directly relevant for a clinical assistant of this kind. Each maps to either regulatory requirements (FDA, ONC) or leading industry frameworks (NIST AI RMF, GMLP, CHAI).
Sentence-Level Source Attribution
In AI drafts, each sentence should link back to the exact source in the patient record, allowing clinicians to quickly check the basis and spot unsupported statements.
The FDA’s clinical decision support guidance requires that physicians can independently review the basis for any recommendation. The ONC’s HTI-1 rule on Decision Support Interventions requires certified health IT systems to expose standardized source attributes. Neither rule mandates sentence-level citations, yet this level of provenance is increasingly seen as a best practice.
NYU introduced sentence-level provenance after the study ended, which means that during the trial, physicians lacked this check.
Uncertainty Signaling in the AI Assistant Interface
When a sentence is unsupported or conflicts with other data, the system should automatically flag it with a visible banner, prompting the physician to review and confirm before approval.
Such banners reflect best practices consistent with ONC expectations for Predictive Decision Support Interventions and the NIST AI Risk Management Framework.
NYU Langone mentioned physician education and decision support as future measures against automation bias. There is no indication that uncertainty banners were part of the tested AI assistant.
QA Sampling and Audit Trails
Well-designed systems should automatically log edits, provenance, and acceptance patterns to create an auditable record that supports systematic quality checks and supplies feedback signals for model self-learning.
QA sampling and audit trails align with NIST recommendations on continuous monitoring and with Good Machine Learning Practice (GMLP) principles for post-deployment safety. They are voluntary today but increasingly expected.
At NYU Langone, quality control relied on a four-part standard (completeness, conciseness, cohesion, and factual accuracy scales) applied by reviewing physicians. Public reports do not mention automated audit analytics.
Metrics for Optimizing AI Safety
Automatically tracking AI safety metrics, such as hallucination and omission rates, the percentage of drafts accepted without edits, and downstream safety signals, helps establish quality thresholds and alert reviewers when the risk increases.
This aligns with the NIST AI Risk Management Framework and the Coalition for Health AI’s assurance guidance. The practice is voluntary but recommended for governance boards and supports the ONC HTI-1 transparency requirements.
NYU Langone plans a randomized trial to measure AI-generated note quality and clinician workload. Public reports do not suggest that artificial intelligence safety metrics were part of the pilot.
ScienceSoft’s Final Note: Does AI Actually Free Up Doctors’ Time?
A recent KLAS survey found that only 16% of US health systems have a system-wide AI governance policy. ScienceSoft sees this gap as a likely reason why AI tools often end up adding to physicians’ workload instead of reducing it.
At NYU Langone, without built-in safeguards, the control over the accuracy of AI-generated notes entirely falls on physicians. In our opinion, in such a situation, the tool may simply shift the clinician’s effort from writing documentation to error-hunting.
Highmark Health and Abridge Aim for In-Visit Prior Authorization With Ambient AI: Here’s the Guardrails It Needs for Compliance

Published: August 25, 2025
On August 12, 2025, Highmark Health, a combined insurer and care system, and Abridge, an ambient AI vendor, announced a plan to co-design and pilot an artificial intelligence workflow that displays insurer prior authorization requirements in real time during clinical visits. The workflow uses the Abridge ambient system integrated with the Epic electronic health record to capture clinically relevant details from the patient and clinician conversation and turn them into a structured note and authorization prompts in real time.
The rollout targets Allegheny Health Network across 14 hospitals and hundreds of clinics. The program builds on Highmark electronic authorization workflows and the Active Gold Carding program, which pre-approves clinicians with high adherence. Highmark operates in Pennsylvania, Delaware, West Virginia, and parts of New York, which means diverse benefit designs and utilization rules.
Where Compliance Can Break
From our experience at ScienceSoft, we see four major compliance risks the IT teams had to address to make visit-time prior authorization feasible.
Risk area 1: Evidence provenance and attribution
Unverifiable or misattributed clinical content can enter the record and be used to justify coverage.
Relevant guardrails include ONC HTI-1 Decision Support Interventions (DSI) transparency requirements for certified health IT that define how to expose evidence provenance.
ScienceSoft expects evidence-linked documentation. Each sentence that supports medical necessity would deep link to the exact transcript or audio snippet inside the chart, consistent with the Abridge concept of Linked Evidence. A robust design would store cryptographic hashes of audio or transcripts and maintain an append-only audit trail that captures model identifiers, prompt templates, inputs/outputs, and the reviewer’s identity. The workflow should block creation of any authorization package until a licensed clinician reviews the evidence-linked note and provides an e-sign-off in the EHR.
Risk area 2: Rule drift and missing required elements
Real-time prompts can reflect outdated or plan-inappropriate criteria. And even with accurate rules, in-visit resolution can stall when required artifacts are not yet available or the coverage path depends on external review.
CMS’s Interoperability and Prior Authorization Final Rule (CMS-0057-F) requires impacted payers to provide 72-hour expedited and 7-day standard decisions with specific denial reasons starting in 2026 and to implement FHIR-based APIs (including Prior Authorization) by 2027.
Where supported, visit-time prompts should be driven by payer FHIR Prior Authorization APIs to pull the active, plan-specific criteria. They can also rely on curated, versioned rule sets to prevent rule drift when APIs are missing. Before submission, the system should run a preflight to verify completeness, coding, and evidence links to catch missing required elements that block in-visit decisions. Each request should be bound to a versioned policy bundle. The platform should record applicable statutory time targets and capture machine-readable approval or denial reasons for the case.
Risk area 3: Over-automation of coverage decisions
If automation becomes the default path, reviewers may rely on the model’s suggestions without independent judgment, losing patient nuance.
CMS clarifies for Medicare Advantage that algorithms may assist, but determinations must be individualized and made by licensed clinicians, not by the algorithm.
We expect a human-in-the-loop gate in the workflow. The system should record the reviewer’s identity and attestation, the model identifier, the prompt template, an input snapshot, the policy bundle ID, timestamps, and the final decision. If any auto-approval mode is used, the system should compile a deterministic checklist of satisfied criteria and link each one to specific sentences in the note. This makes the linkage to patient-specific data auditable. This proves that the decision relied on the patient’s actual data.
Risk area 4: Privacy, tracking, and consent
Silent data leakage or unlawful recording can create HIPAA violations, state-level consent failures, and improper handling of substance use disorder information.
Relevant frameworks include the HIPAA Privacy and Security Rules, HHS/OCR guidance on tracking technologies, applicable state all-party consent laws, and 42 CFR Part 2.
ScienceSoft would handle this by shipping clinical apps without third-party trackers on authenticated screens and using only telemetry covered by BAAs. We expect the tech vendor to use similar safeguards during the rollout. The stack should enforce multifactor authentication, least-privilege access, encryption at rest and in transit, and immutable audit logs for every data touch. Location-aware consent orchestration should block recording until consent is captured and stored as an artifact, with a persistent recording indicator in the clinic and in telehealth. Sensitive content should be labeled and excluded from authorization payloads unless consent explicitly covers it. Strong egress controls should apply to any export.
Microsoft’s MAI-DxO Turns General LLM Into Diagnostic Panel. How Does It Work, and What Are the Limits?


Published: August 21, 2025
In late June 2025, Microsoft reported the accuracy benchmarking results for its experimental diagnostic AI agent, Microsoft AI Diagnostic Orchestrator (MAI-DxO). MAI-DxO paired with OpenAI’s o3 was 4× more accurate than physicians (85.5% vs 19.9%). Moreover, an MAI-DxO version that incorporated a spend cap cut the average testing spend from $7,850 per case for the off-the-shelf model to $2,396, while keeping accuracy near 80%.
What Microsoft Actually Built (and What It Didn’t)
Microsoft didn’t train a brand-new medical model. What MAI-DxO actually does is add a model-agnostic orchestration layer on top of an off-the-shelf LLM (e.g., OpenAI o3), without task-specific fine-tuning. The agent comprises the following components:
- SDBench — a Sequential Diagnosis Benchmark that turns 304 NEJM CPC cases into stepwise sessions where the agent and physicians start from a short vignette, ask questions, order tests, and then commit to a diagnosis.
- Gatekeeper — an LLM-based controller that uses OpenAI o4 mini with full access to each patient case, including the final diagnosis, and reveals only what a matching question or ordered test would show.
- Judge — a grader that uses OpenAI o3 and a clinician-written rubric to score the final diagnosis on a 1 to 5 scale, where 4 counts as correct.
- Orchestrator — a single LLM (OpenAI o3) plays a five-person panel that maintains and updates the differential (Dr. Hypothesis), selects informative next tests (Dr. Test Chooser), challenges the current hunch (Dr. Challenger), tracks costs (Dr. Stewardship), and checks requests (Dr. Checklist).
Where Orchestration Beats Costly Fine-Tuning and Where It’s Not Enough
From what ScienceSoft has seen, building an MAI-DxO-style agent is expected to take months. The effort centers on the orchestration layer that encodes roles and consensus. No task-specific weight updates are required.
For comparison, we can consider Google AMIE, a custom-trained diagnostic agent with recent peer-reviewed publications (Nature, 2025) on conversational diagnostic artificial intelligence (however, clinical deployment evidence remains limited). Building an AMIE-style agent takes years. IT teams must generate large volumes of realistic clinical dialogues to cover common and rare scenarios, annotate for safety and quality, and run repeated cycles of fine-tuning to shape agent behavior.
This is a clear example that orchestration and agentic workflows can sometimes rival expensive fine-tuning.
Where orchestration is not enough
- Imaging and other signals. Many diagnoses hinge on reading scans, waveforms, or slides. Orchestration cannot give a base model these skills. Options include importing finalized radiology or cardiology reports from the EHR or imaging system, adding a separate imaging AI module, or training a multimodal model.
- Local protocols and formularies. Stroke pathways, sepsis bundles, antimicrobial restrictions, and insurer prior authorization rules vary by institution. An orchestrator can reference local policy via the retrieval augmented classification (RAC) module and rules. If decisions must be phrased and enforced exactly to match the site’s policies, targeted fine-tuning or rule engines become necessary.
- Language and locale. General models can converse in many languages, but clinical nuance, abbreviations, and code sets are local. For multilingual regions, organizations should pair orchestration with language-specific prompts, terminology maps, and retrieval over local content. If the assistant will have to draft native-quality clinical notes in multiple languages, partial fine-tuning or domain adapters are often required.
- Documentation style and coding. Health systems use structured templates, specific problem lists, and coding taxonomies. Orchestration can guide the format. When an exact note style or auto-coding to ICD and SNOMED is mandatory, IT teams have to add templating, coding services, or model adapters trained on local notes.
- Legal and policy language. Consent text, disclaimers, and jurisdiction-specific phrasing must be precise. Adding a retrieval (RAC) module and policy templates usually works. If those statements need to be generated in free text under tight constraints, fine-tuning or rule-based assembly is safer.
Cedars-Sinai’s AI Platform Delivered 24/7 Care to 42,000 Patients. Strong Custom Deployment, but Is There a Scalable, Publicly Accessible Alternative?
Published: August 4, 2025
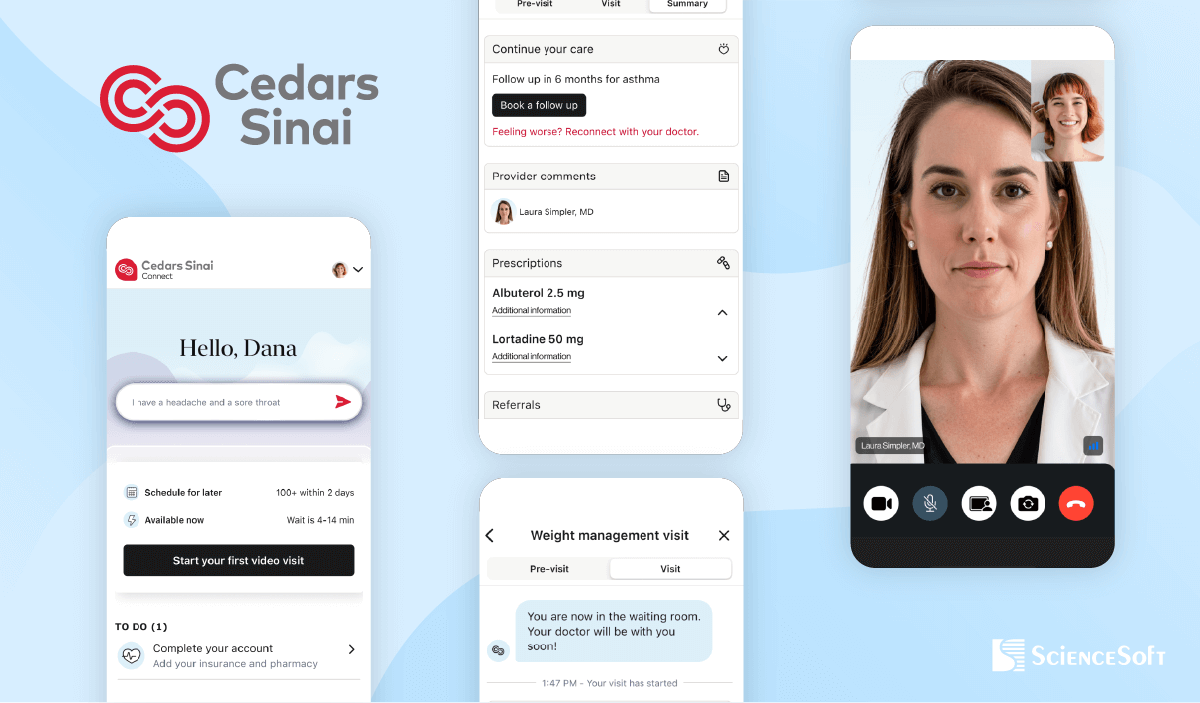
Cedars-Sinai, a large Los Angeles-based healthcare organization serving over 1 million patients annually, launched its AI-powered virtual care platform, CS Connect, in 2023. Developed in partnership with K Health, the AI-powered solution delivers 24/7 primary and urgent care support.
Patients begin by interacting with a chatbot that collects symptom information. The system analyzes this input alongside relevant data from the patient’s EHR to generate a summary and preliminary treatment recommendation. A physician then reviews the AI’s output, asks follow-up questions if needed, accepts or modifies the recommendations, and signs off on the final treatment plan.
According to an article published by Business Insider on Wednesday, July 23, 2025, approximately 42,000 patients have utilized the platform. A 2025 study comparing initial AI treatment recommendations in CS Connect with final recommendations of physicians who had access to the AI recommendations and may or may not have viewed them showed that when physician and AI recommendations differed, the AI recommendations were more frequently rated as optimal (77.1%) compared with treating physician decisions (67.1%).
A Strong Example of AI in Clinical Operations
The system reflects a sophisticated hybrid AI–physician workflow. The AI handles intake and preliminary clinical reasoning, while physicians remain final decision-makers. This balance ensures safety and fosters clinician trust, critical for scaling AI in healthcare.
While the article doesn’t detail the full tech stack, it states that CS Connect was built using K Health’s virtual care platform. Public sources suggest the platform’s underlying proprietary AI model was trained on anonymized clinical data from over 400 million doctors’ notes, licensed from Maccabi Healthcare, Mayo Clinic, and K Health’s own cases. This extensive dataset provides the model with strong clinical reasoning capabilities.
The platform was reportedly integrated with Cedars-Sinai’s EHR to support personalized artificial intelligence recommendations tailored to each patient’s specific context.
What Alternatives to Proprietary Models Are Available Today?
The key advantage of K Health’s proprietary artificial intelligence model is that it was trained and fine-tuned on anonymized real patient records.
Public LLMs, such as OpenAI’s GPT-4o, and Amazon Nova offer remarkable capabilities, especially in conversation. But they haven’t been trained on clinical data at the scale or depth of K Health’s system, and can’t reliably support diagnosis without extensive grounding. Google’s MedLM likely comes closest as an off-the-shelf clinical model. According to ScienceSoft’s team, an alternative not involving custom training may look as follows:
- MedLM for diagnosis.
- GPT-4o or AWS Nova Sonic for human-like conversation.
- FHIR-based RAG layer to pull patient context from the EHR.
- LangGraph for agent orchestration.
- LiveKit for real-time media communication.
- Tavus.io for video avatars.
This agentic, component-based architecture enables real-time logic, clinical context enrichment, and HIPAA-compliant interaction without needing a massive proprietary dataset.
A Platform Any Hospital Can Build Faster Than Ever
While platforms like CS Connect draw on proprietary clinical datasets and long-term optimization, the advancement of healthcare-tuned models like Google’s MedLM brings medical-grade reasoning into reach for a broader range of providers. Combined with structured prompts and a secure RAG layer, such solutions can help healthcare providers of all sizes rapidly build AI-assisted triage and clinical support tools.
These systems may not yet rival the real-world pattern recognition of models trained on 400+ million patient notes, but they enable accurate, guideline-based recommendations and explainability, without requiring years of custom model development.
Mount Sinai Launches AI Voice Assistant for Pre-Procedure Calls. Smart Use Case, but Technical Transparency Lags

Published: July 24, 2025
Mount Sinai Hospital in New York has introduced Sofiya, an AI-powered voice assistant that contacts patients before cardiac catheterization procedures. According to an article published in Becker’s Hospital Review on Tuesday, July 8, 2025, Sofiya provides pre-procedure instructions, answers logistical questions, and handles complex, multi-turn conversations. It was developed through close collaboration between a team of healthcare professionals and computer engineers, and is said to have saved over 200 nursing hours in five months. More than 800 calls were reviewed during the initial rollout, with reported patient satisfaction above 95%.
High-impact, yet low-risk initiative
Pre-procedure coordination is a mission-critical yet non-diagnostic area, where risks are lower and immediate value can be delivered. It addresses a clear operational pain point and achieves measurable results, which few AI pilots manage to do.
Critical implementation details are missing
While Mount Sinai has not disclosed the underlying technology behind Sofiya, the following analysis reflects ScienceSoft’s informed speculation based on industry standards and the capabilities described.
Technology stack
Mount Sinai’s AI assistant Sofiya likely runs on a fine-tuned LLM or a carefully prompt-engineered commercial model like GPT used in a HIPAA-compliant way, e.g., via Azure OpenAI Service. To achieve domain fluency, the team probably used a mix of de-identified nurse–patient call transcripts, structured procedural scripts, and synthetic dialogues, which is a common practice among AI teams prioritizing PHI safety.
The assistant’s calm, natural voice suggests the use of a neural text-to-speech (TTS) system. Microsoft’s Azure AI Speech–Voice Live API, which enables low-latency audio generation using Custom Neural Voice technology, is a likely candidate. This level of personalization is key for trust in patient-facing interactions.
AI performance monitoring
The manual review of 800 calls is a solid start, but there’s no mention of ongoing monitoring mechanisms for AI performance. The system may use tools like Azure Monitor, Azure Application Insights, or Amazon CloudWatch to monitor performance metrics and send automated notifications to the security team in case of suspicious changes.
Regulatory compliance
Although there is no explicit mention of HIPAA compliance, the system likely operates in an audited, encrypted, and access-controlled environment (e.g., Azure Virtual Network or Amazon Virtual Private Cloud). It may also rely on Microsoft’s Azure AI Content Safety or Amazon Bedrock Guardrails to track and filter all interactions between the assistant and patients in real time, helping prevent unauthorized disclosures and detect threats like prompt injection attempts.
For further analysis, explore another example of a high-impact yet low-risk AI application in healthcare.

